
📄 About Me
I am a master’s student at the Institute of Automation, Chinese Academy of Sciences (CASIA), affiliated with the National Laboratory of Pattern Recognition. I am supervised by Prof. Haiyun Guo and under the leadership of Prof. Jinqiao Wang. I am also a member of the Zidongtaichu Foundation Model Research Center. I am currently an intern at the Wenxin (ERNIE Bot) team at Baidu.
My research centers on two directions:
- Multimodal Retrieval: I explore reasoning-enhanced retrieval paradigms, fine-grained instance-level retrieval, and composed image retrieval. Representative works include TRACE, PLUME, REIR/CLARE, UniFGVC, WISER, and ReCALL.
- Unified Understanding-Generation Models: I investigate how to leverage generation capabilities to assist understanding in unified multimodal models, with applications in spatial reasoning and degraded image understanding. Representative works include COOPER and CLEAR.
🔥 News
- 2026.02: 🎉🎉 Our paper “COOPER” was accepted to CVPR 2026!
- 2026.02: 🎉🎉 Our paper “WISER” was accepted to CVPR 2026!
- 2026.02: 🎉🎉 Our paper “ReCALL” was accepted to CVPR 2026!
- 2025.07: 🎉🎉 Our paper “Referring Expression Instance Retrieval and A Strong End-to-End Baseline” was accepted to ACM MM 2025!
- 2025.07: Started research internship at Baidu Wenxin (ERNIE Bot) team.
- 2025.01: Joined Zidongtaichu for research internship on foundation models.
📝 Publications
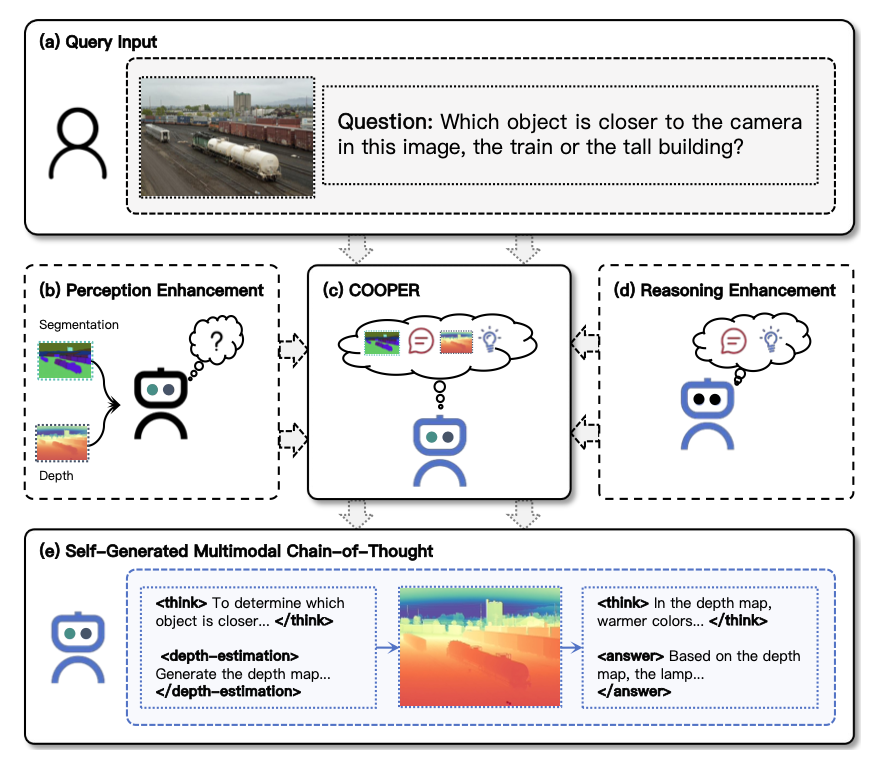
COOPER: A Unified Model for Cooperative Perception and Reasoning in Spatial Intelligence
Zefeng Zhang*, Xiangzhao Hao*, Hengzhu Tang, Zhenyu Zhang, Jiawei Sheng, Xiaodong Li, Zhenyang Li, Li Gao, Daiting Shi, Dawei Yin, Tingwen Liu
- We propose a cooperative perception-reasoning unified framework for spatial intelligence, where the model autonomously generates auxiliary visual information (e.g., depth maps) as part of a multimodal chain-of-thought.
- Designed a SFT+GRPO two-stage framework with Cooperative Perception-Reasoning Reward, achieving 6.91% average improvement on spatial reasoning benchmarks.
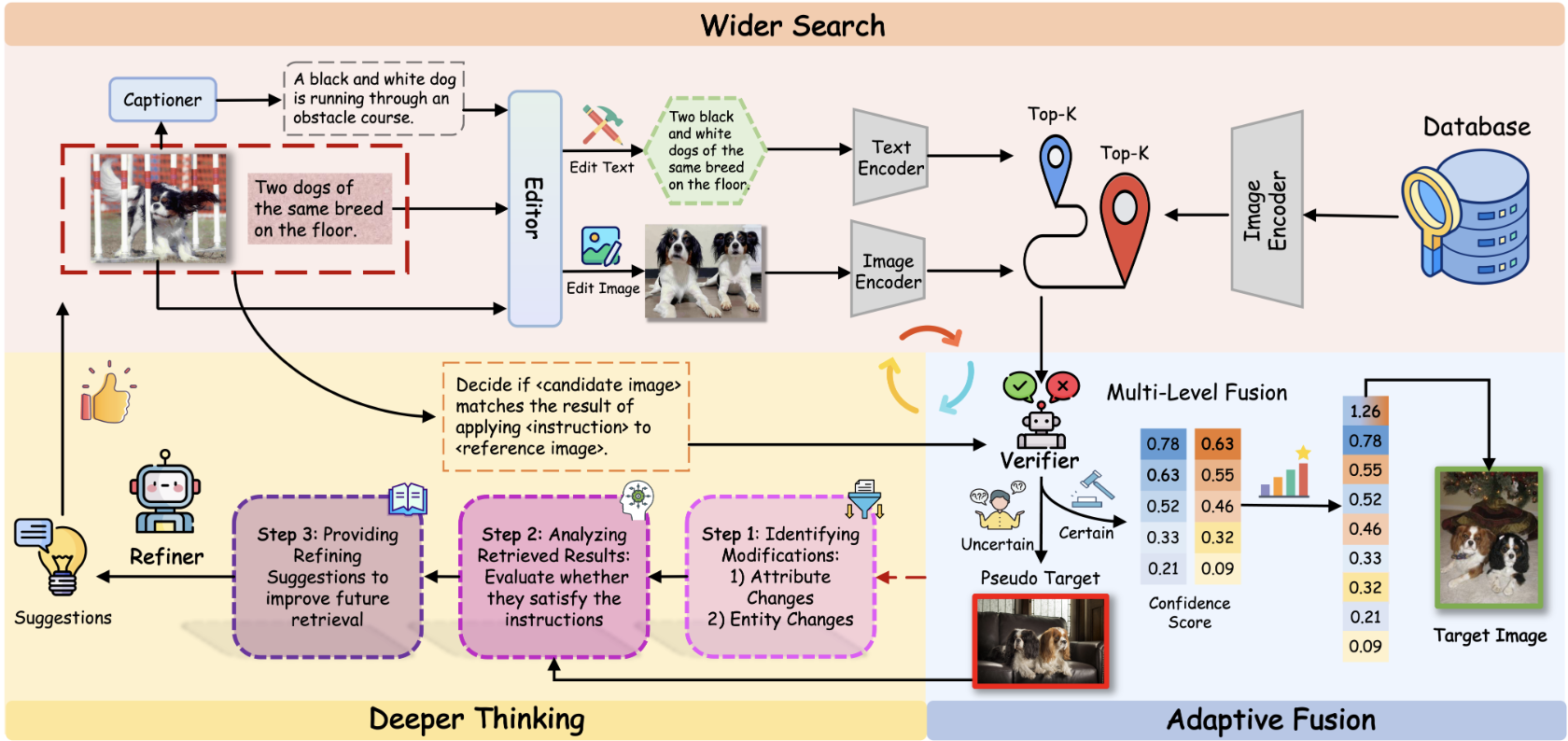
Tianyue Wang, Leigang Qu, Tianyu Yang, Xiangzhao Hao, Yifan Xu, Haiyun Guo, Jinqiao Wang
- We propose WISER, a training-free framework for zero-shot composed image retrieval with wider search, deeper thinking, and adaptive fusion.
- Achieves 45% relative improvement on CIRCO mAP@5 and 57% on CIRR Recall@1 over prior training-free methods, even surpassing many training-based approaches.
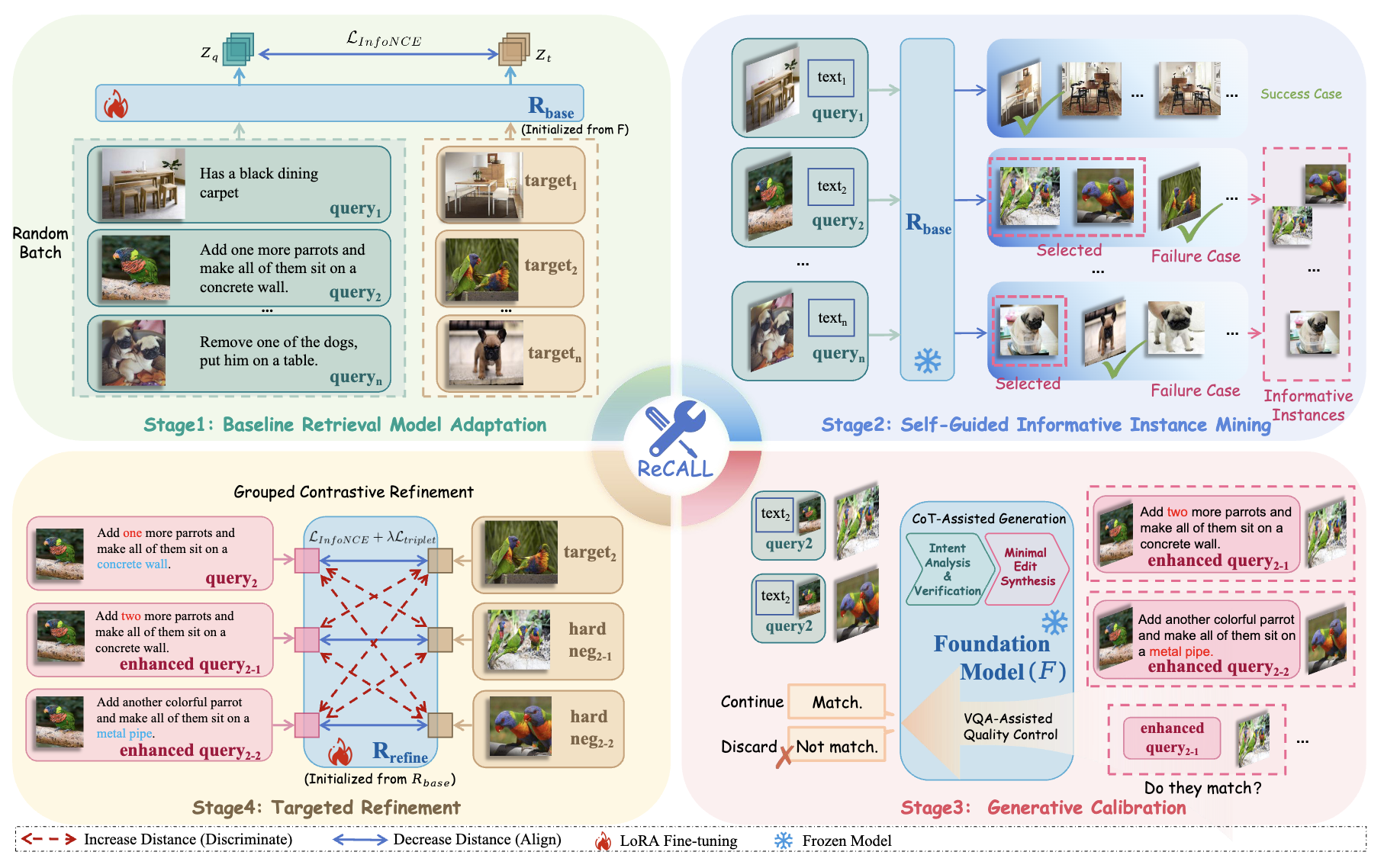
ReCALL: Recalibrating Capability Degradation for MLLM-based Composed Image Retrieval
Tianyu Yang, Chenwei He, Xiangzhao Hao, Tianyue Wang, Jiarui Guo, Haiyun Guo, Leigang Qu, Jinqiao Wang, Tat-Seng Chua
- We propose ReCALL, an iterative training framework for MLLM-based composed image retrieval with hard negative mining and foundation model data augmentation.
- Effectively recalibrates capability degradation in MLLMs for composed image retrieval tasks.
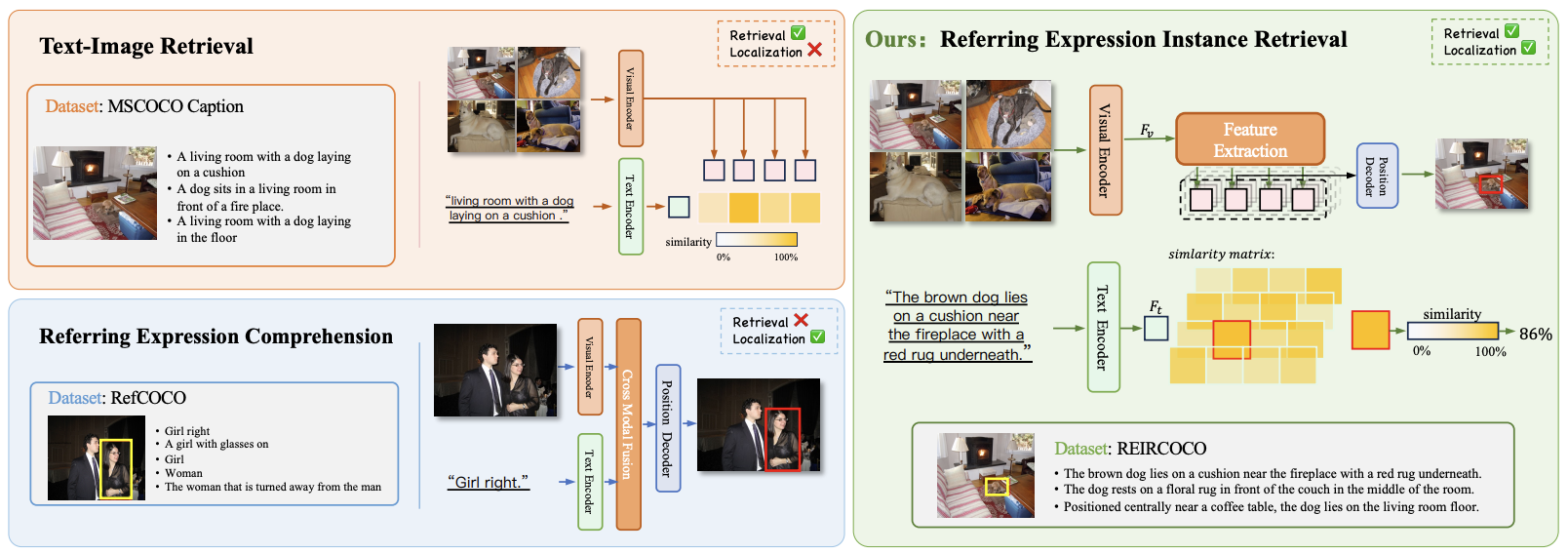
Referring Expression Instance Retrieval and A Strong End-to-End Baseline
Xiangzhao Hao, Kuan Zhu, Hongyu Guo, Haiyun Guo, Ning Jiang, Quan Lu, Ming Tang, Jinqiao Wang
- We propose a novel multimodal task—Referring Expression Instance Retrieval (REIR), which aims to retrieve and localize a specific object instance from a gallery of images based on a natural language description.
- Constructed the first large-scale dataset REIRCOCO (30K+ images, 215K+ instances, 613K+ descriptions) and proposed end-to-end dual-stream model CLARE.
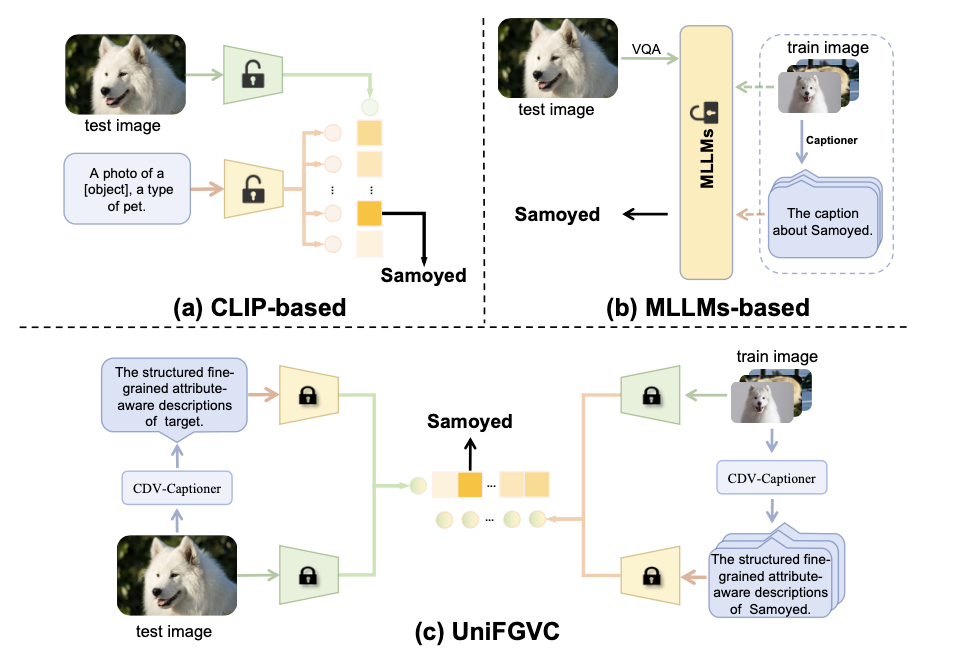
UniFGVC: Universal Fine-Grained Vision Classification via Multimodal Retrieval
Hongyu Guo, Xiangzhao Hao*, Jiarui Guo, Haiyun Guo, Jinqiao Wang, Tat-Seng Chua
- We reformulate few-shot fine-grained visual classification as a multimodal retrieval problem and design CDV-Captioner for CoT-guided discriminative descriptions.
- Surpasses existing few-shot SOTA by 5.52% across 12 FGVC benchmarks, also outperforming multiple fully-supervised MLLM methods.
📋 Under Review
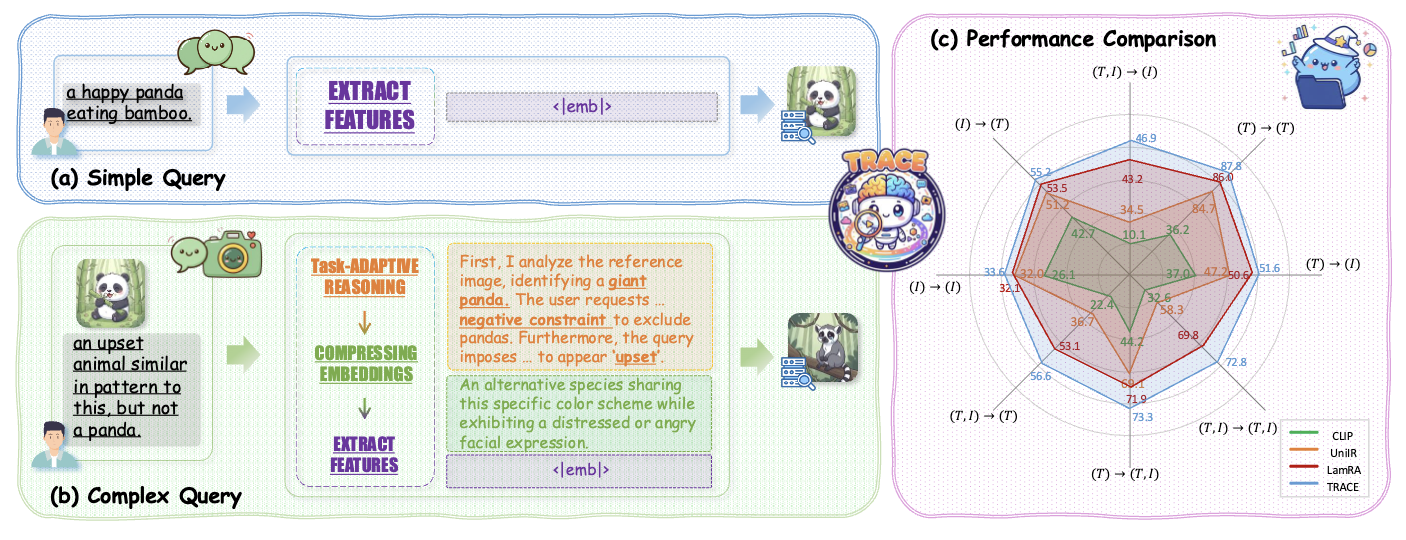
TRACE: Reasoning-Guided Representation Learning for Universal Multimodal Retrieval
Xiangzhao Hao, Shijie Wang, Tianyu Yang, Tianyue Wang, Haiyun Guo, Jinqiao Wang
- We propose a “reason-then-encode” retrieval paradigm. TRACE integrates task-adaptive CoT generation with discriminative representation learning in MLLMs, with a difficulty-aware routing strategy that autonomously decides whether to activate reasoning.
- Built M-BEIR-CoT large-scale dataset and achieved SOTA on M-BEIR benchmark with strong zero-shot transfer on 13 unseen datasets.
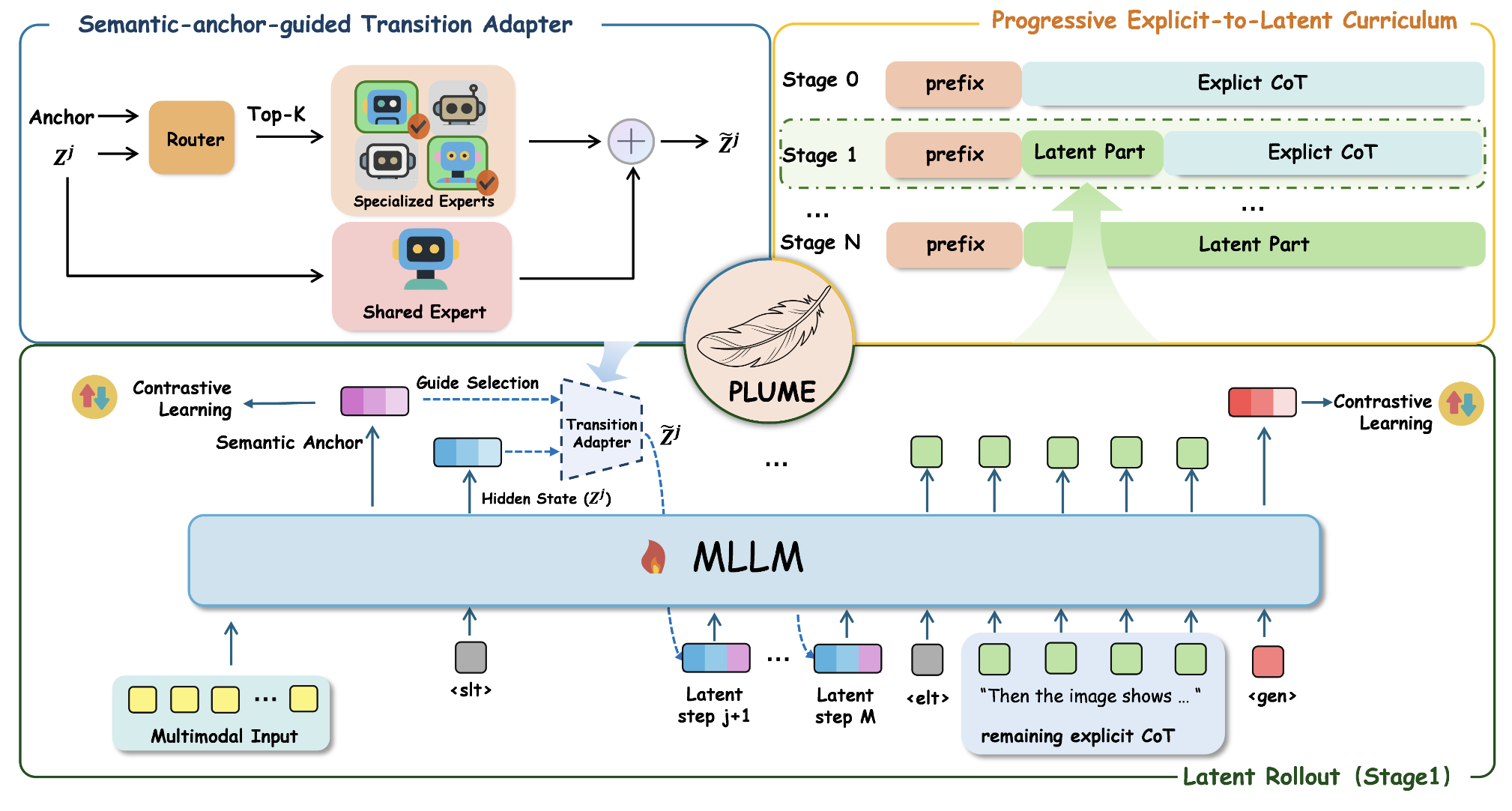
PLUME: Latent Reasoning Based Universal Multimodal Embedding
Chenwei He*, Xiangzhao Hao*, Tianyu Yang, Yuxiang Ma, Yuheng Jia, Lingxiang Wu, Chaoyang Zhao, Haiyun Guo, Jinqiao Wang
- We propose PLUME, internalizing explicit CoT into latent reasoning trajectories with only 8 latent steps, achieving 30.3x inference speedup over explicit CoT methods.
- Achieves 61.6 overall score on MMEB-v2 benchmark (78 tasks), outperforming UME-R1 and VLM2Vec-V2, with significant gains on video (+1.9) and visual document (+3.6) tasks.
💻 Internships
- 2025.07 - Present, Baidu - Wenxin (ERNIE Bot) Team, Beijing, China.
- Participated in ERNIE Bot 5.0 pretraining: data processing, cleaning pipeline, and benchmark evaluation.
- Worked on ernie-one unified understanding-generation model pretraining: architecture survey, thinking-then-generation and interleaved generation data pipeline development, and continued pretraining experiments.
- 2025.01 - 2026.06, Zidongtaichu - Foundation Model Research Center, Beijing, China.
- Trained the image-text retrieval module of the Zidongtaichu embedding model.
- Contributed to local retrieval project, enabling efficient multimodal early warning in the Shiyukunchuan Large Model.
📖 Educations
- 2023.09 - 2026.06 (expected), M.Eng. in Pattern Recognition, Institute of Automation, University of Chinese Academy of Sciences. GPA: 3.76/4.00.
- 2019.09 - 2023.06, B.Eng. in Computer Science and Technology (Second major: Mathematics and Applied Mathematics), School of Intelligence and Computing, Tianjin University. Ranked 6/139, GPA: 3.87/4.00.
💡 Patents
- Zhu Kuan, Guo Haiyun, Hao Xiangzhao, Tang Ming, Wang Jinqiao. Multi-turn Image-Text Understanding and Localization Method and Device Based on Unified Multimodal and Multi-form Representations. CN202411282777.1 [P]. 2024-10-18.
- Zhu Kuan, Guo Haiyun, Hao Xiangzhao, Tang Ming, Wang Jinqiao. Image-Text Information Processing Method, Apparatus, Device, Storage Medium, and Program Product. CN202411297843.2 [P]. 2025-02-11.
🎖 Honors and Awards
- 2024.06 UCAS Outstanding Student (三好学生) and Excellent Student Leader (优秀学生干部)
- 2023.09 Second Prize in the National Final of the Loongson Cup (National Student Computer System Capability Challenge)
- 2023.07 Huawei MindSpore Scholarship
- 2023.06 Tianjin Outstanding Graduate (天津市优秀毕业生), Tianjin University Outstanding Student
- 2023.03 Meritorious Winner (一等奖), Mathematical Contest in Modeling (MCM/ICM)
- 2022.11 Silver Award, 7th China Internet+ Innovation and Entrepreneurship Competition (Tianjin)
- 2022.09 Second Prize, North China Five-Province Computer Application Competition